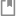 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 预估时间
- 前提条件
- 操作示例
- 第一步:设置熔断规则
- 第二步:设置客户端
- 第三步:触发熔断机制
在微服务中,系统的各个服务之间在网络上存在大量的调用,在调用过程中,如果某个服务繁忙或者无法响应请求,可能会引发集群的大规模级联故障,从而造成整个系统不可用,引发服务雪崩效应。当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用,达到服务降级的效果,通过牺牲局部保全整体的措施就叫做熔断(Circuit Breaking)。
本文基于示例应用 Bookinfo,演示如何对其中的一个服务设置熔断规则,并通过一个负载测试客户端 (fortio) 来触发熔断机制,在 KubeSphere 中演示熔断现象。
预估时间
约 15 分钟。
前提条件
已完成了 Bookinfo 微服务的灰度发布 示例中 查看流量监测 之前的所有步骤。
操作示例
第一步:设置熔断规则
使用项目普通用户 project-regular 登录 KubeSphere,进入示例应用 Bookinfo 的详情页。由于在 查看流量拓扑图 步骤中,通过 watch 命令引入真实的访问流量后,此时在流量治理中可以看到流量治理拓扑图。
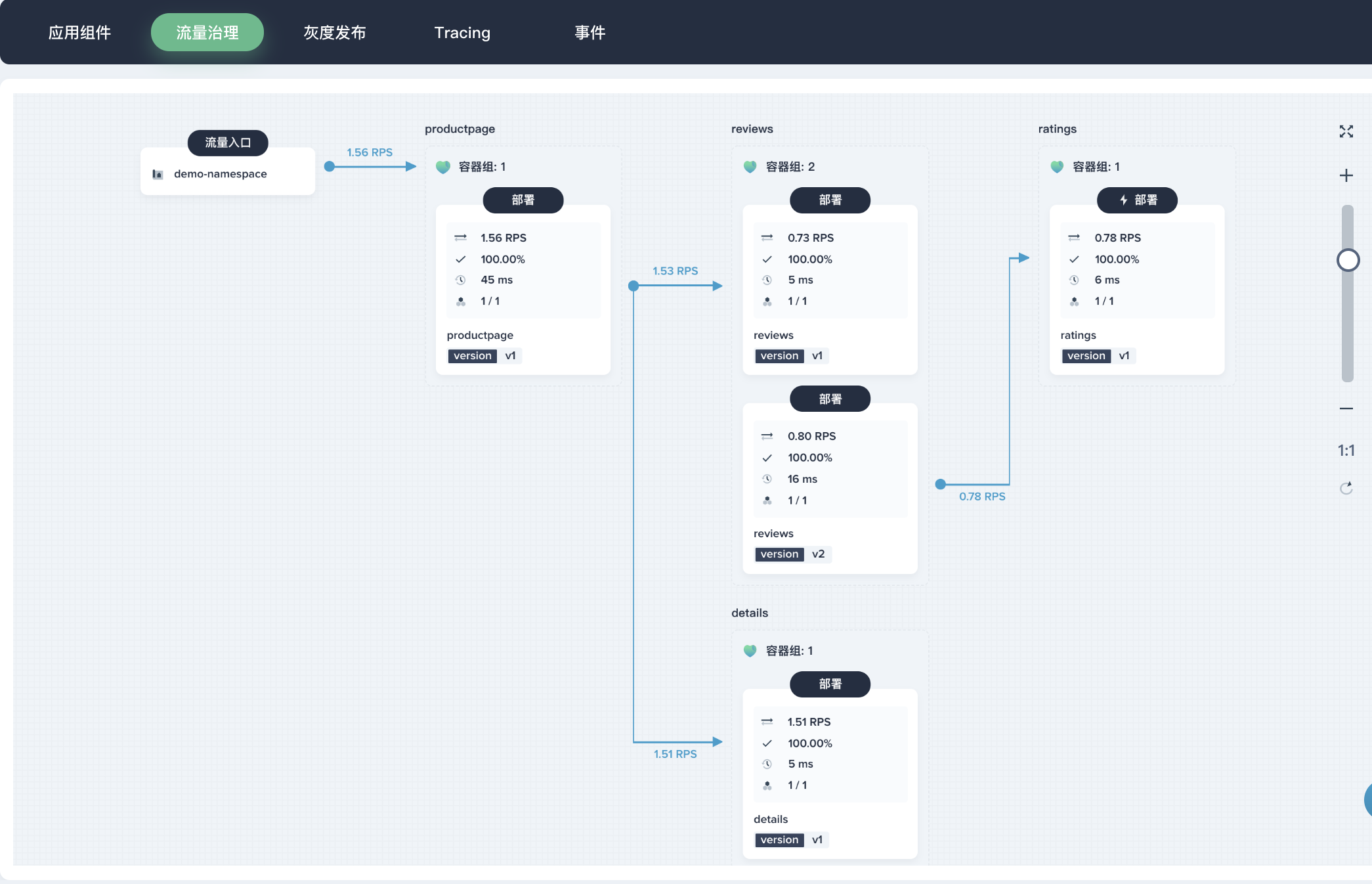
1、点击 ratings,在右侧展开 「流量治理」,打开 「连接池管理| 和 「熔断器」,参考如下设置。
- 连接池管理:将
最大连接数和最大等待请求数(等待列队的长度)都设置为1,表示如果超过了一个连接同时发起请求,Istio 就会熔断,阻止后续的请求或连接; - 熔断器:参考如下设置,表示每
1秒钟扫描一次上游主机,连续失败5次返回 5xx 错误码的100%数量的主机 (Pod) 会被移出连接池180秒,熔断器参数释义详见 流量治理 - 熔断器- 连续错误响应(5xx)个数:5;
- 检查周期(单位: s):1;
- 容器组隔离比例(单位: %):100;
- 短隔离时间(s):180。
连接池参数说明:
- 最大连接数:表示在任何给定时间内, Envoy 与上游集群(比如这里是 ratings 服务)建立的最大连接数,适用于 HTTP/1.1;
- 每连接最大请求数:表示在任何给定时间内,上游集群中所有主机(比如这里是 ratings 服务)可以处理的最大请求数。对后端连接中最大的请求数量若设为 1 则会禁止 keep alive 特性;
- 最大请求重试次数:在指定时间内对目标主机最大重试次数;
- 连接超时时间:TCP 连接超时时间,最小值必须大于 1ms。最大连接数和连接超时时间是对 TCP 和 HTTP 都有效的通用连接设置;
- 最大等待请求数 (等待列队的长度):表示待处理请求队列的长度,默认为 1024。如果该断路器溢出,集群的
upstream_rq_pending_overflow计数器就会递增。
2、完成设置后,下拉至底部点击 「确定」,保存规则。
第二步:设置客户端
由于我们已经在 reviews-v2 中 reviews 容器中注入了负载测试客户端 (fortio),它可以控制连接数量、并发数以及发送 HTTP 请求的延迟,能够触发在上一步中设置的熔断策略。因此可以通过 reviews 容器来向后端服务发送请求,观察是否会触发熔断策略。
1、使用集群管理员账号 admin 登入 KubeSphere,在右下角找到小锤子图标,然后打开 kubectl (或直接 SSH 登录集群任意节点)。
2、执行以下命令登录客户端 Pod (reviews-v2) 并使用 Fortio 工具来调用 ratings 服务,-curl 参数表明只调用一次,返回 200 OK 表示调用成功。
$ FORTIO_POD=$(kubectl get pod -n demo-namespace | grep reviews-v2 | awk '{print $1}')$ kubectl exec -n demo-namespace -it $FORTIO_POD -c reviews /usr/bin/fortio -- load -curl http://ratings:9080/ratings/0HTTP/1.1 200 OK···
第三步:触发熔断机制
1、在 ratings 中设置了连接池管理的熔断规则,最大连接数 和 最大等待请求数(等待列队的长度) 都设置为 1,接下来设置两个并发连接(-c 2),发送 20 请求(-n 20):
$ kubectl exec -n demo-namespace -it $FORTIO_POD -c reviews /usr/bin/fortio -- load -c 2 -qps 0 -n 20 -loglevel Warning http://ratings:9080/ratings/0···Code 200 : 18 (90.0 %)Code 503 : 2 (10.0 %)···
2、以上可以看到,几乎所有请求都通过了,Istio-proxy 允许存在一些误差。接下来把并发连接数量提高到 3:
$ kubectl exec -n demo-namespace -it $FORTIO_POD -c reviews /usr/bin/fortio --load -c 3 -qps 0 -n 30 -loglevel Warning http://ratings:9080/ratings/0···Code 200 : 22 (73.3 %)Code 503 : 8 (26.7 %)···
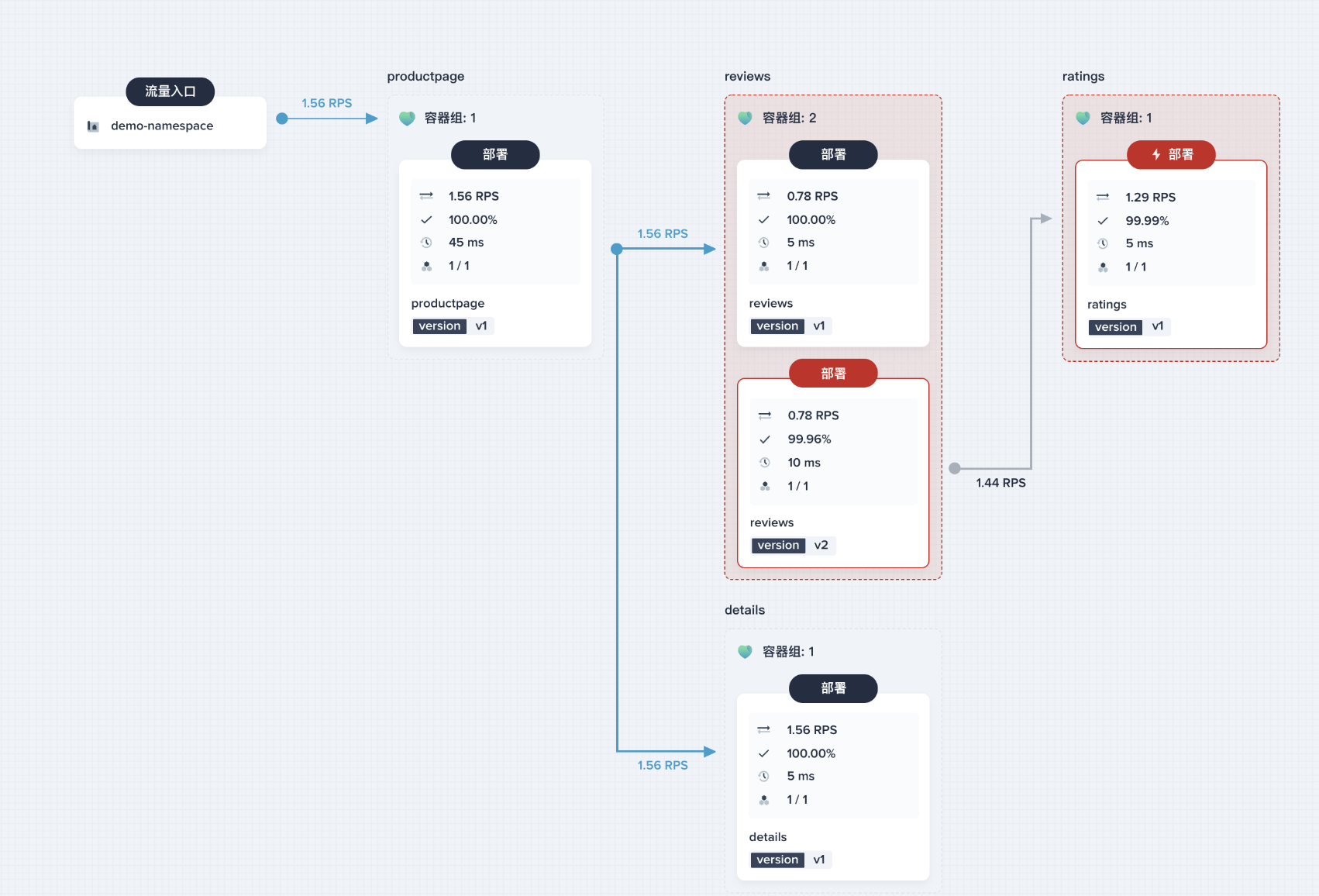
3、查看结果发现熔断行为按照之前的设置规则生效了,此时仅 73.3 % 的请求允许通过,剩余请求被断路器拦截了。由于此时 503 的返回次数为 8,超过了预先设置的连续错误响应(5xx)个数 5,此时 ratings 的 Pod 将被 100% 地隔离 180 s,ratings 与 reviews-v2 之间也出现了灰色箭头,表示服务间的调用已断开,ratings 被完全隔离。
4、可以给 reviews-v2 的部署 (Deployment) 添加如下一条 annotation,即可查询 ratings 的 istio-proxy 的状态。在 「工作负载」→ 「部署」列表中找到 reviews-v2,点击右侧 ··· 选择 「编辑配置文件」,添加一条 sidecar.istio.io/statsInclusionPrefixes 的 annotation。
···annotations:sidecar.istio.io/inject: 'true'sidecar.istio.io/statsInclusionPrefixes: 'cluster.outbound,cluster_manager,listener_manager,http_mixer_filter,tcp_mixer_filter,server,cluster.xds-grpc'···
完成后点击 「更新」。
5、查询 istio-proxy 的状态,获取更多相关信息。如下所示 upstream_rq_pending_overflow 的值是 10,说明有 10 次调用被熔断。
$ kubectl exec -n demo-namespace -it $FORTIO_POD -c istio-proxy -- sh -c 'curl localhost:15000/stats' | grep ratings | grep pending···cluster.outbound|9080|v1|ratings.demo-namespace.svc.cluster.local.upstream_rq_pending_overflow: 10cluster.outbound|9080|v1|ratings.demo-namespace.svc.cluster.local.upstream_rq_pending_total: 41···
